PromptLoop delivers enterprise-grade AI automation with market-leading accuracy through our carefully designed task system. We achieve this by combining advanced AI models with structured workflows and built-in confidence scoring to give you clarity and control over your results.
This system is built on transparency. It is designed to allow teams to set up a PromptLoop task, quickly test it on real data and websites, run it on a sample of 10-20 inputs to further validation, and then confidently use the same task thousands of times without fear of hallucination or model error. Every dataset that you run on the platform includes a suite of analysis tools to search through to find which items were found, not found, and which websites were not reachable. This suite also includes automatic improvement allowing you to select edits and changes for retraining and constant model improvement.
Our platform is designed to provide reliable, consistent outputs at scale. We achieve this through:
To provide transparency and enable quality control, we offer detailed confidence scoring on tasks. This helps teams:
Our models evaluate three key factors when determining confidence:
Below is a general rubric for how to interpret the scores. These are not 100% accurate, but across a large sample size provide useful insights.
10 - There are no clear difficulties in completing the task for the specified input. Across a dataset or larger job, responses should exceed 95% accuracy.
7 - There is some level of difficulty in one of the specified categories. Across a dataset or larger job, responses should exceed 80% accuracy.
5 - There are several, significant areas of difficulty. Across a dataset or larger job, responses should still exceed 60% accuracy.
1-4 - There is a major difficulty detected in the task or the website context and it is unlikely the results will be reliable for the input.
Right now the three factors are combined together, but as we continue to improve the scoring these will be separated allowing you (and Promptloop automatically) to adjust tasks to improve confidence and accuracy.
Confidence scores can be seen whenever you run a task in the task test page underneath the results next to the avg. runtime. They are also available within the analysis page of full dataset runs where you can see the confidence score for each row of data run.
PromptLoop offers build in analysis tools to make it easy to view and understand results. The goal of these tools are to provide visibility into where tasks performed well and where tasks might need to be modified to improve accuracy with a particular source.
The analysis page is automatically generated for any job launched on a dataset. For each Dataset you will see a Jobs icon at the top of the page where you can quickly navigate to the analysis page. Each analysis generated graphics so you can quickly see which datapoints were returned.
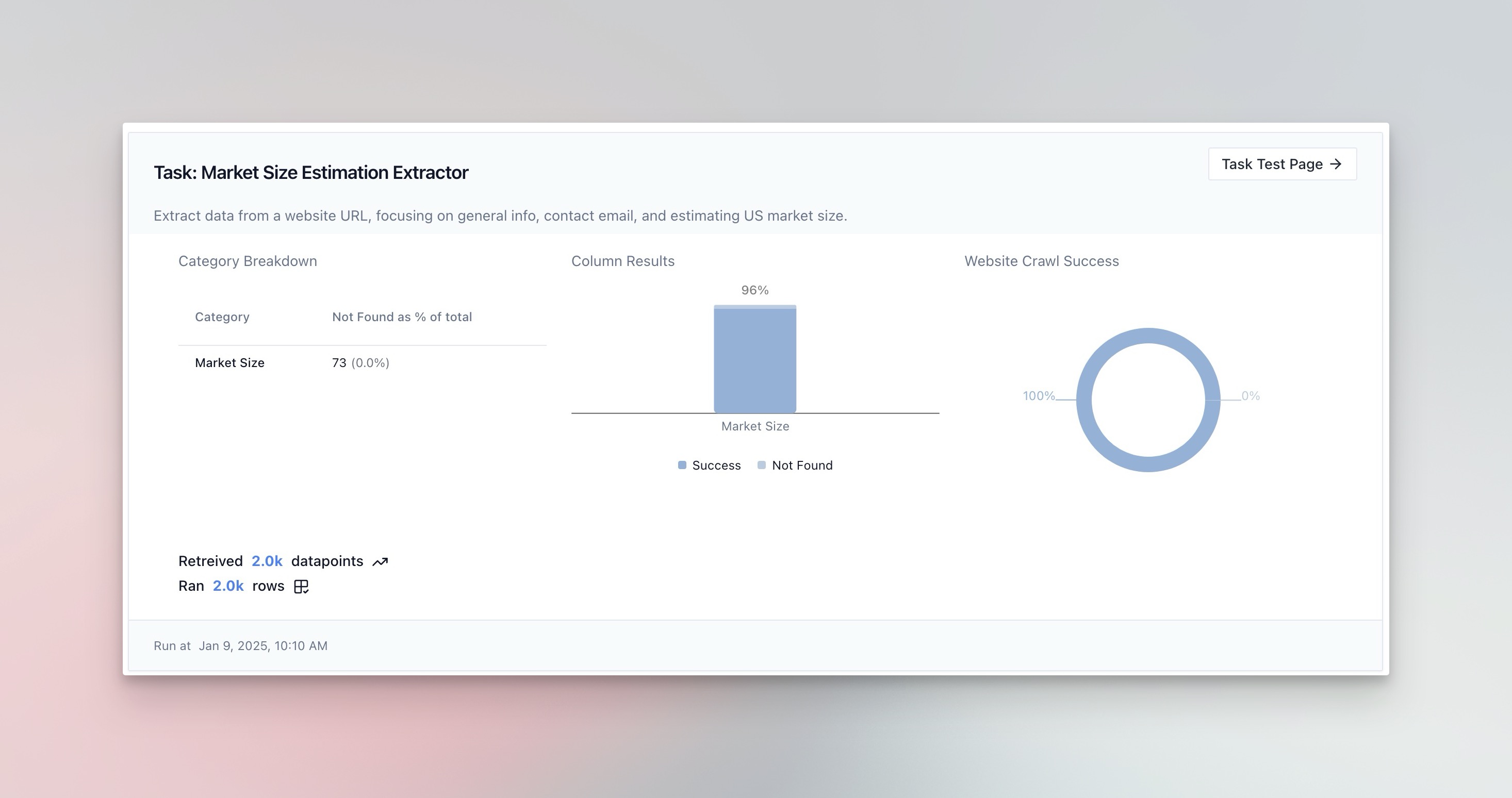
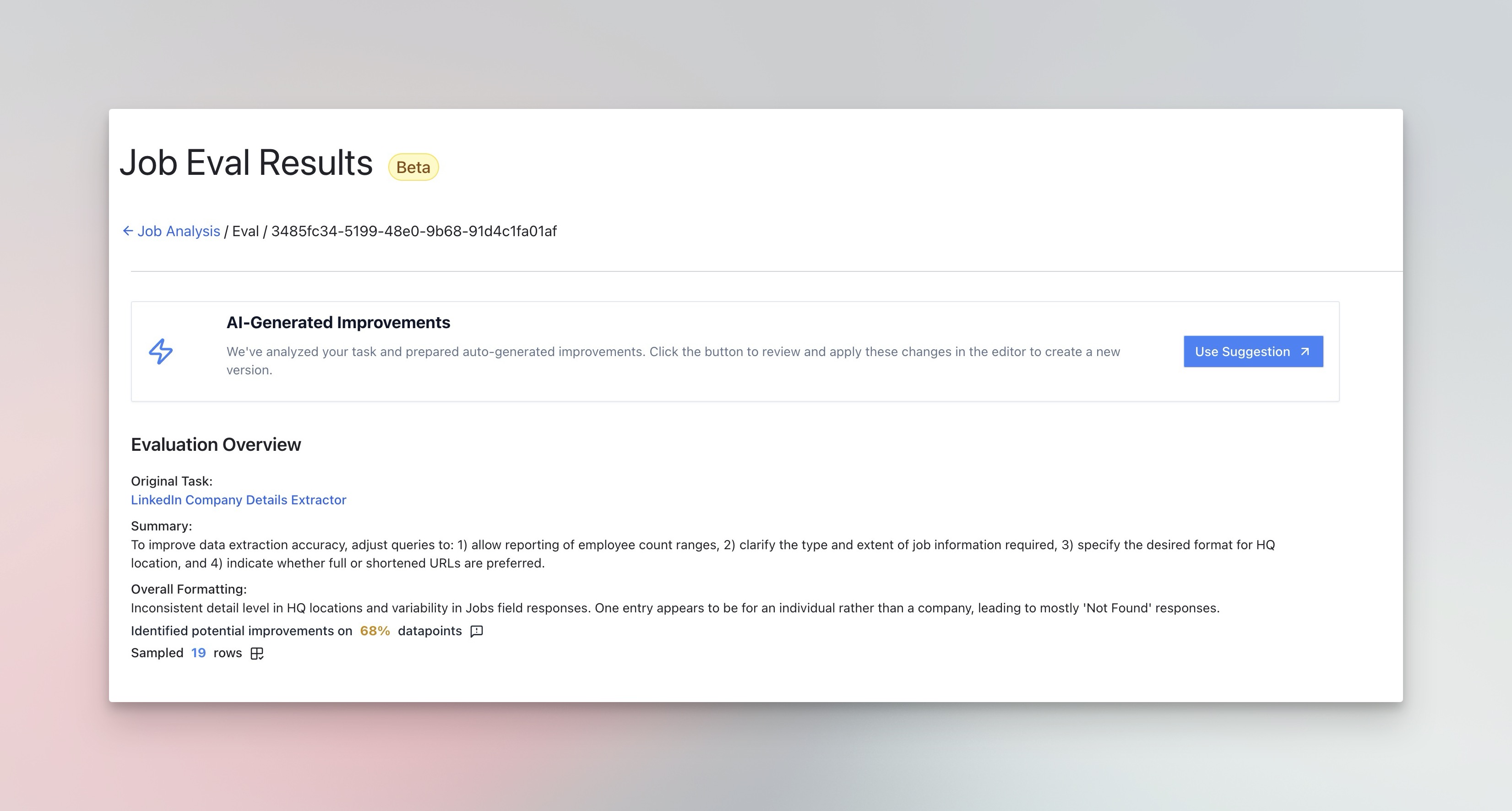
PromptLoop offers auto Evals that you can run on results to use an analysis model to review responses. This feature provides high level guidance and suggestions for how, if at all, you might improve your task. It will auto suggest improvements that you can use to create a new version.
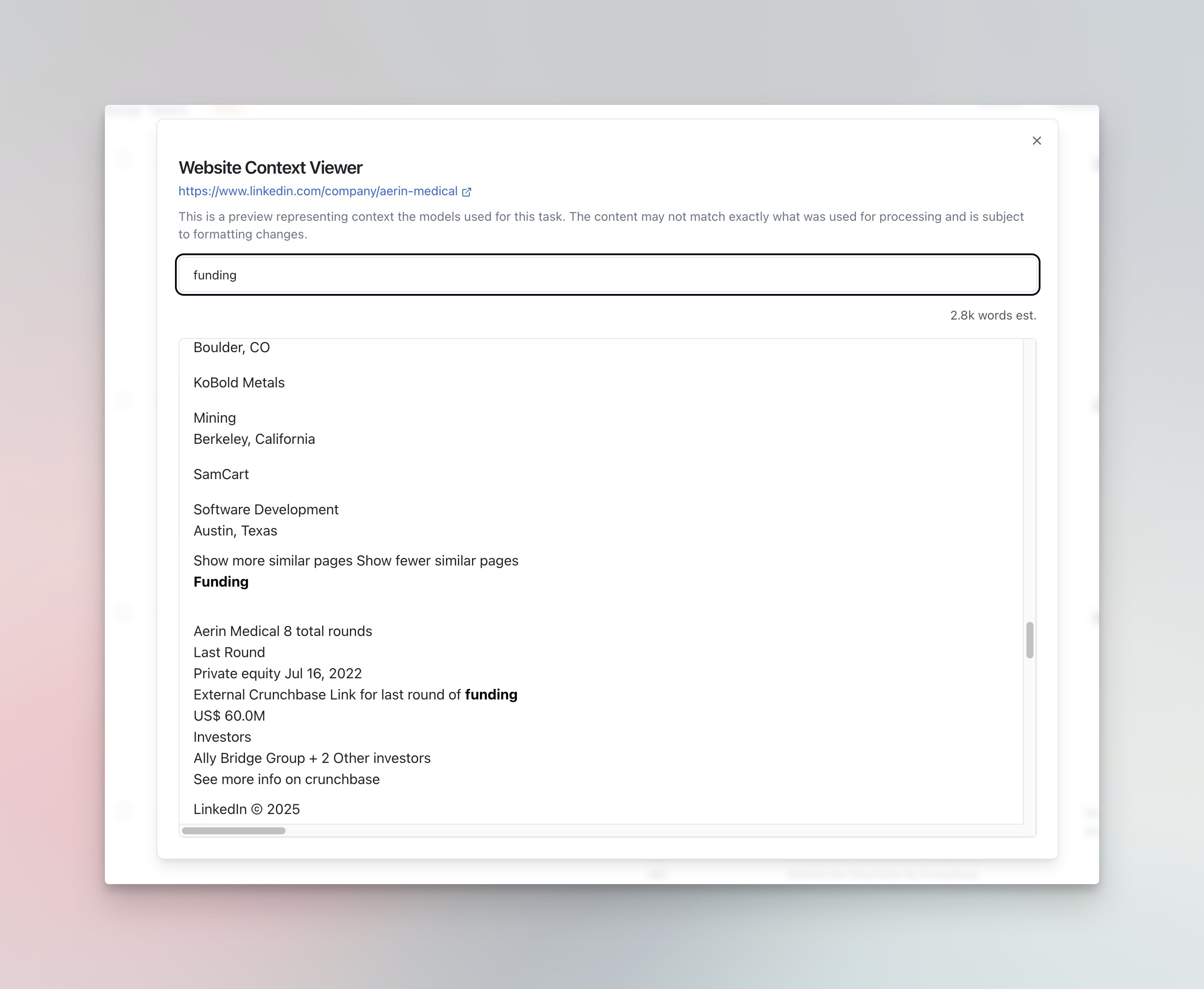
The analysis page provides the ability to view exactly what input information the models had access to, which links were navigated too, and more depending on the task.
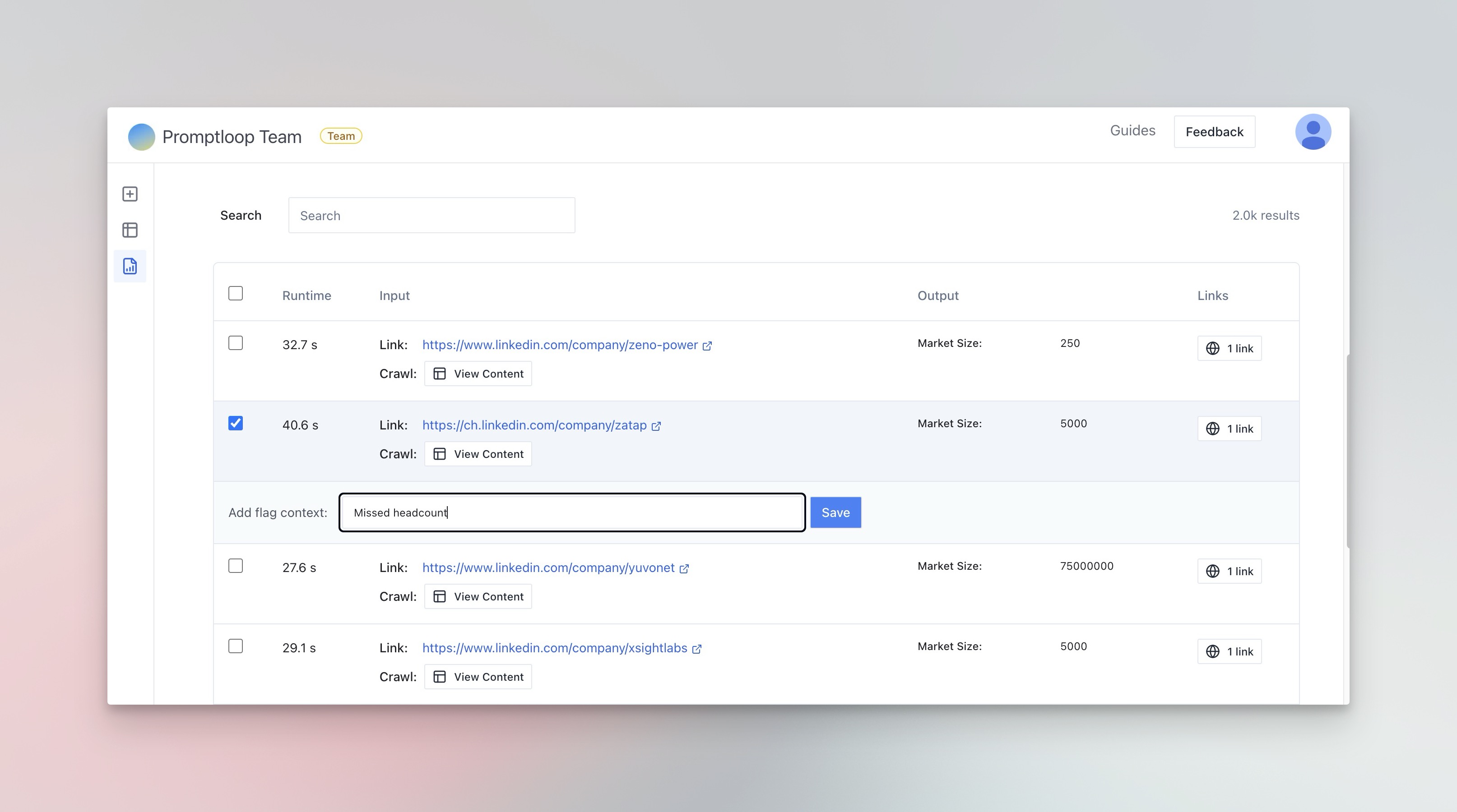
For each response, you can now add direct feedback and corrections for inputs where the model did not perform as expected. These are then picked up in future training for system improvements on your models.
To maximize accuracy:
For enterprise users, we offer:
Need help optimizing your task accuracy? Contact our team for guidance on confidence scoring implementation and best practices.