Getting Started
Getting StartedNew
Capabilities
Web Browsing
Scraping Lists
Dynamic Data Extraction
Signals
Accuracy & Confidence
Research Pages
Integrations
Integrations
These docs are for the legacy list only extraction. We have combined list extraction into the same flow as normal web crawling and data extraction. This is the best place to start for almost all tasks. Read those docs here.
Unlike the web browsing or search tasks that return one row of data per input, the list tasks allow you to pull many rows of data from a website. This is useful in many instances such as pulling a list of all of a company's locations, a list of board members, portfolio companies from a venture capital company's website, or any other instance of structured data present on a website.
Before PromptLoop, extracting a list of structured data took either significant manual work or a lot of complex python. Even with AI models that can write code for you this can be error prone. We designed list tasks to allow you to simply define the columns for the items (e.g Name, Position, and phone number if you are extracting a list of persons) and pass in any instructions for what you do or don't want to extract ("Return any people who work in the IT department or are part of the C-Suite"). Then you can run this on a list of websites and (get number of websites x number of entities of data per website) rows back.
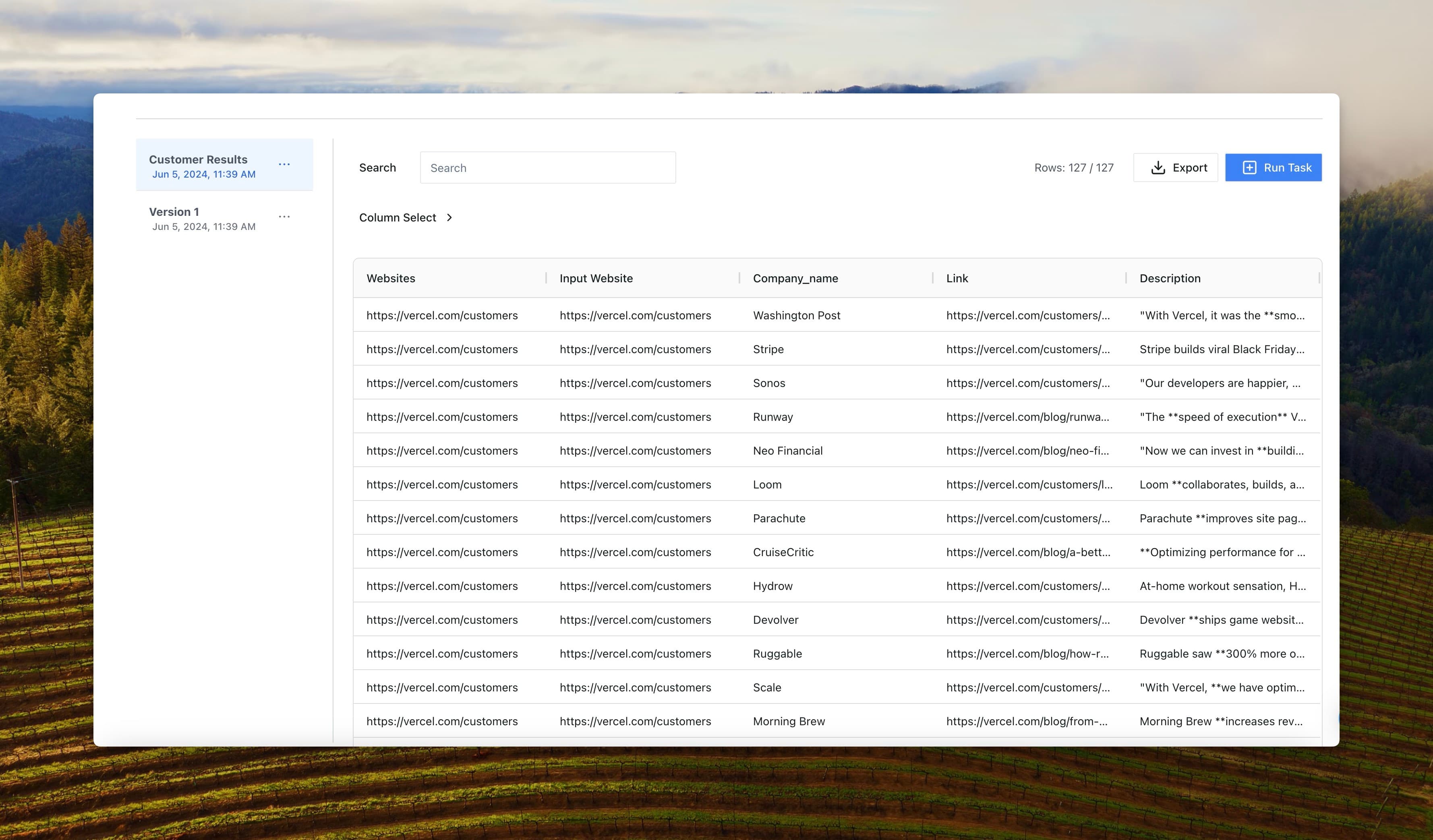
We have spent a tremendous amount of time iterating, testing, and improving the list extraction flow around two core tenets: minimize false extractions, and provide as much context around the extraction to allow our users to implement it into their needs with confidence.
Minimizing false extractions in practice means ensuring that our models aren’t assuming unrelated information on the website is an entity and gets extracted as this can significantly decrease the efficacy of a dataset when you are pulling lists from thousands of sites.
In order to maximize accuracy we split up the list extraction into two main steps. First we use a fine tuned reasoning model to determine the exact number of entities present on a site that meet the provided description. Once we have this number we then use another flow of models to pull these entities. Our list extraction task is close to 100% accurate with lists under 100 items (100 items on each page) and the entity count is much more accurate as we get higher. This allows our customers to use the entity count, which is returned in addition to the list of actually extracted entities, as a source of truth as to how well the extraction worked.
What does it mean if entity_count doesn't match the number of returned entities? When you run a list task you will receive the entity_count as well as the number of actual extracted entities. There are a couple of scenarios where these values will not be the same.
This depends on the complexity of the object you are extracting (whether you are pulling many fields for each object), but we have seen very high levels of success up to hundreds of items.
For the base template, yes you need to start from the page with the list you want to extract on it. If you want to use the more advanced crawling list extract (that navigates around the site looking for matching entities), reach out to the team to get access.
Data is immediately saved and can be searched and filtered before you export your information.
You can use the Datasets page to use list results as the basis for further research tasks and to save and share versions with your team.
Search and Exploration
PromptLoop provides list tasks specifically geared to collection of places and map data like that found on search engines like Google Maps.
To leverage this task, you can navigate to the example in the task library or in the playground.
The Map Data tasks by taking an input to specify the geography and a search term. To keep results geographically accurate, map data is provided for specific geo bound searches which might overlap. To extract hits for certain cities or states you can run successive searches on a dataset of locations and return all the listed results together by setting up a dataset.
Results are returned with places data intact and up to date at time of search. You can also leverage our geographies datasets here.
US Zip Codes Top Population Zip Codes
Current Map data is limited to the United States but custom geographies can be added on request
Advanced list building engines are available to our enterprise customers where results can be customized and jobs can run over much larger datasets. This can include fully automated list building, help integrating data into your systems (CRM, database etc) and more.
Our default list extraction works by just going to the page inputted, loading it as thoroughly as possible and then extracting the entities you are looking for in structured format. For some use cases, however, the list is spread across various parts of the website. This might be a paginated list; a website with multiple categories, each containing relevant items; or any of the other many different iterations of web extraction!
To handle this we have a smart crawl list extract task that intelligently navigates through the website using user provided instructions as to what to look for. After navigating through the website, the entities are then pulled from each site, put together and deduplicated as a whole. This is an important step as often items may be duplicated on various parts of the website, so this ensures you are getting a list of unique items.
This isn’t necessarily the best solution for all list extraction use cases. Often single page list extract is more accurate (as well as faster). Get in touch with the team and we will work together to figure out if this type of task will work well for your needs!
If you are looking for advanced extraction options, we suggest you get in touch for a demo here.
Want to explore and try this today but don't have an account yet? You can set one up and try this for free right now.